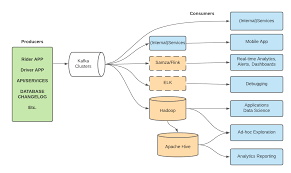
Real-time data streaming has become an essential component of today’s organizations. Organizations want efficient and dependable solutions to handle and analyze data in real-time in an era where data-driven decision making is key. Apache Kafka and message queues are two common options for real-time data streaming. In this post, we will look at the features, strengths, and use cases of Apache Kafka and message queues, as well as the distinctions between the two.
Getting to Know Apache Kafka
As a highly scalable and distributed streaming technology, Apache Kafka has grown in popularity. It is well-known for its ability to process enormous amounts of data in real time. Let’s look at some of Apache Kafka’s important features:
The distributed architecture of Kafka enables for horizontal scaling, fault tolerance, and high throughput. It employs a publish-subscribe approach in which producers write data to topics and consumers subscribe to those topics in order to consume the data. This architecture ensures that data is distributed efficiently across several nodes.
Persistent Storage: Kafka offers long-term and fault-tolerant data storage. It ensures that communications are reliably preserved, even in the event of a failure. This feature allows for data replayability, which allows customers to consume data at their own pace or replay data for historical study.
Stream Processing: The Streams API in Kafka allows for real-time stream processing. It enables developers to create apps that can process and alter data streams in real time. This capability paves the way for strong real-time analytics and data processing.
Use Cases for Apache Kafka
Apache Kafka is useful in a variety of situations. Among the most notable are:
Real-time Analytics: Because Kafka can handle high-velocity data, it’s an ideal solution for real-time analytics. Organizations may instantaneously get insights and make data-driven choices, allowing them to respond quickly to changing market conditions or client needs.
Log Aggregation: Kafka aggregates and consolidates log data from many sources in an efficient manner. This allows enterprises to monitor and analyze system logs in real time. Kafka facilitates troubleshooting by centralizing log data and providing a comprehensive view of the system.
Event Sourcing: Because of its durability and replayability, Kafka is well-suited for event sourcing architectures. Events are saved as a stream of data in event sourcing, preserving data integrity and supporting event-driven systems.
Investigating Message Queues
Message queues have long been used for asynchronous communication and dependable messaging. They provide a means for system decoupling, allowing diverse components to communicate effectively. Let’s look at some of the most important aspects of message queues:
Message Queues use a queuing model, which stores messages in a queue until they are digested by the intended recipients. This allows for asynchronous communication by decoupling the sender and receiver. It also ensures that messages are sent reliably even if the recipient is temporarily unavailable.
Patterns of Point-to-Point and Publish-Subscribe: Both point-to-point and publish-subscribe messaging patterns are supported by message queues. Each message in the point-to-point approach has a single recipient. The publish-subscribe paradigm, on the other hand, permits messages to be disseminated to numerous subscribers.
Guaranteed Delivery: Message queues ensure that messages are delivered to customers on a consistent basis. They frequently include procedures like as acknowledgments and retries to ensure message delivery. This capability is especially vital in mission-critical situations when message loss is unacceptably high.
Use Cases for Message Queues
Message queues are useful in a variety of situations. Among the most prevalent use cases are:
Offloading of Resource-Intensive jobs: Message queues can be used to offload resource-intensive jobs to distinct components. This improves scalability and performance by allowing jobs to be processed individually and at a reasonable speed.
Event-Driven Architecture: Organizations can build event-driven designs by decoupling components via message queues. This promotes loose coupling and scalability in complex systems by allowing components to react to events and interact asynchronously.
Message Queues in a Microservices Architecture: Message queues provide a reliable communication mechanism between services in a microservices architecture. They enable effective inter-service communication by ensuring seamless data flow and coordination across distinct microservices.
Message Queues vs. Apache Kafka
While both Apache Kafka and message queues provide real-time data streaming demands, they have differences that make them suited for different circumstances. Here are some examples of comparisons:
Scalability and throughput: Apache Kafka excels at managing large amounts of data while also allowing for significant scalability. Its distributed architecture allows for seamless scaling over additional nodes while maintaining high throughput and low latency. Message queues, on the other hand, are frequently more lightweight and ideal for cases that do not require the same amount of scalability.
Message Retention and Replayability: Because of its persistence and log-based storage, Kafka is suited for circumstances in which data must be saved and replayed. Its capacity to hold messages for a longer amount of time and provide data replay benefits use cases such as real-time analytics and event sourcing. In contrast, message queues often promote quick message consumption above long-term retention.
Point-to-Point vs. Publish-Subscribe: The publish-subscribe model of Kafka makes it suited for use scenarios in which messages must be published to numerous subscribers. This is useful in applications such as real-time analytics, where data must be ingested by several users at the same time. Message queues flourish in cases where each message has a single recipient due to its point-to-point architecture.
Apache Kafka has a robust ecosystem and substantial tooling support, making it a popular choice among developers. It offers data system interfaces, stream processing frameworks, and monitoring tools. While message queues provide tooling and integration choices, the Kafka ecosystem is more mature and provides a wider range of functionality.
Conclusion
Choosing the correct real-time data streaming solution is critical for enterprises looking to efficiently exploit data. Apache Kafka and message queues both offer distinct advantages and applications. Because of its strengths in high-throughput applications, log-based storage, and publish-subscribe patterns, Apache Kafka is a popular choice for real-time analytics and event sourcing. Message queues are particularly effective for point-to-point messaging, job offloading, and microservices communication. Understanding the exact requirements of your use case will assist you in making an informed choice between these two alternatives.

